Are algorithms doomed to be racist and harmful, or is there a legitimate role for them in a just and equitable society?
Algorithms have been causing disproportionate harm to low- and middle-income individuals, especially people of color, since long before this current age of machine learning and artificial intelligence. Two cases in point: neighborhood redlining and credit scores. While residential redlining was a deliberately racist anti-black practice [1], FICO-based credit scoring does not appear to have been created from a racist motive. By amplifying and codifying existing inequities, however, the credit score can easily become another tool for racial oppression [2].
Still, with appropriate measures in place, and a bit of pragmatic optimism, perhaps we can find ways to achieve the scalability/impartiality goals of algorithms while upholding true equity and justice.
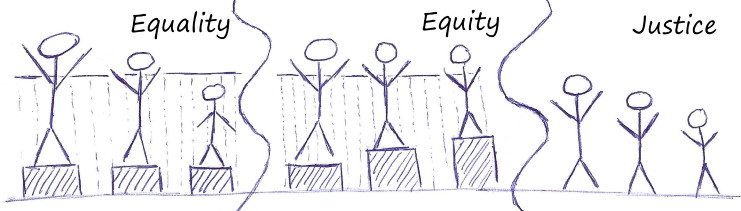
Justice: changing conditions, removing the barriers. Could not find the original
source to credit, so I drew my own version of this thought-provoking graphic. I
leave the sport being played behind the fence up to your imagination.
Fresh out of college I served as an AmeriCorps*VISTA at a non-profit dedicated to supporting small business development for women and minorities. There I began learning about the detrimental effects, deliberate and insidious, of so many modern policies around finance and housing. Later when I became a full-time employee, I was given a mission: come up with a rubric - an algorithm - for pre-qualifying loan applicants. The organization only had so much money to lend, and to remain solvent it would need to ensure that most loans would be repaid in full. Could we come up with a scoring mechanism that would help focus our attention on the most promising opportunities, bring a measure of objectivity and accountability, and yet remain true to our mission?
The organization was founded and, at that time, run by Jeannette Peten, an African American woman with a background in business finance and a passion for helping small businesses to succeed. Where credit scores attempt to judge credit worthiness through a complex calculation based on repayment histories, she asked me to take a broader approach that was dubbed the Four C’s of lending: Cash Flow, Character, Credit, and Collateral. Thus: what manner of calculation, utilizing these four concepts, would yield a useful prediction of a potential borrower’s capacity and capability to thrive and repay the loan?
Roughly following a knowledge engineering [3] approach, we brainstormed simple scoring systems for each of the C’s, with Character counting disproportionately relative to the others. To avoid snap judgment and bias, Character especially had to be treated through careful inference rather than subjective opinion, and thus was drawn from multiple sources including public records, references, site visits, business training and experience, and more.
Then I applied the scores to existing borrowers for validation: would the successful borrowers have made the grade? No? Tweak the system and try again. And again. And when a handful of great businesses in the target demographic were still on the borderline, my mentor identified additional “bonus points” that could be given for high community impact. I do not recall any formal measurement of model fitness / goodness beyond the simple question: does this model include more of our pool of successful loan applicants than all other models? Admittedly this was an eyeball test, not a rigorous and statistically valid experiment.

Machine learning is the automated process of creating models, testing them against a sample, and seeing which yields the best predictions. Then (if you are doing it right) cross-validating [4] the result against a held-out sample to make sure the model did not over-fit the training data. In a simplistic fashion, I was following the historical antecedent of machine learning: perhaps we can call it Human Learning (HL). As a Human Learning exercise, I was able to twiddle the knobs on the formula, adjusting in a manner easily explained and easily defended to another human being. Additionally, as an engineer whose goal was justice, rather than blind equality, it was a simple matter to ensure that the training set represented a broad array of borrowers who fell into the target demographic.
In the end, the resulting algorithm did not make the lending decisions for the organization, and it required human assessment to pull together the various criteria and assign individual scores. What it did accomplish was to help us winnow through the large number of applicants, identifying those who would receive greater scrutiny and human attention.
Nearly twenty years ago, we had neither the foresight nor the resources to perform a long-range study evaluating the true effectiveness. Nevertheless, it taught this software engineer to work harder: don’t use the easy formula, make sure the baseline data are meaningful and valid for the problem, listen to domain experts, and most of all treat equity and justice as key features to be baked in rather than bolted on.

Algorithms are increasingly machine-automated and increasingly impacting our lives, all too often for the worse. The MIT Technology Review summarizes the current state of affairs thus:
“Algorithms now decide which children enter foster care, which patients receive medical care, which families get access to stable housing. Those of us with means can pass our lives unaware of any of this. But for low-income individuals, the rapid growth and adoption of automated decision-making systems has created a hidden web of interlocking traps.”[5]
On our current path, “color-blind” machine learning will continue tightening these nets that entrap those “without means.” But it does not have to be that way. With forethought, care, and a bit of the human touch, I believe we can work our way out of this mess to the benefit of all people. But it’s gonna take a lot of work.
Resources
- The History of Redlining (ThoughtCo), Redlining in America: How a history of housing discrimination endures (Thomson Reuters Foundation). Potential modern version: Redlined by Algorithm (Dissent Magazine), Modern-day redlining: How banks block people of color from homeownership (Chicago Tribune).
- Credit scores in America perpetuate racial injustice. Here’s how (The Guardian). Counterpoint from FICO: Do credit scores have a disparate impact on racial minorities?. Insurance is another arena where “color-blind” algorithms can cause real harm: Supposedly ‘Fair’ Algorithms Can Perpetuate Discrimination (Wired).
- Knowledge Engineering (ScienceDirect).
- What is Cross Validation in Machine learning? Types of Cross Validation (Great Learning Blog)
- The coming war on the hidden algorithms that trap people in poverty (MIT Technology Review)
Posted with : Tech, Social Discourse, Justice, Inclusion and Anti-Racism, Data Analytics and Visualization